Objective
The focus of this project was centered on applying deep learning architectures to process and interpret medical data, specifically diagnoses codes from the International Classification of Diseases, Tenth Revision (ICD-10). This application of deep learning is an effort to address the main research question, how could sequences of diagnosis codes be predicted for future patient visits? Within the context of Beth Israel Hospital in Boston, Massachusetts we found that of the patients who died while admitted between 2008 and 2019, 10% experienced cardiac arrest. Of those who experienced cardiac arrest, 75% of those patients passed away during their stay at the hospital. If we could analyze a patient’s medical history in the form of the chronological sequence ICD-10 diagnoses, could we accurately predict the sequences of diagnoses that might follow from a subsequent hospital visit in order to improve treatment options, patient health outcomes, and decrease mortality rates?
Methodology
Two models were used for the analysis. The first was a sequence-to-sequence encoder decoder GRU-based model with a Bahdanau attention mechanism, implemented with Pytorch and Jupyter Notebooks. This model was a text-generative AI model which used prior sequences of ICD-10 codes to output the next predicted sequences of ICD-10 codes. The second model was a Bidirectional Encoder Representation Transformer (BERT) model, also implemented in Pytorch and Jupyter Notebooks. This is an encoder only model with multi-headed attention and positional encoding which classifies if a sequence of ICD-10 codes follows the previous sequence of ICD10 codes, essentially treating diagnosis prediction as a binary text classification problem.
Conclusions
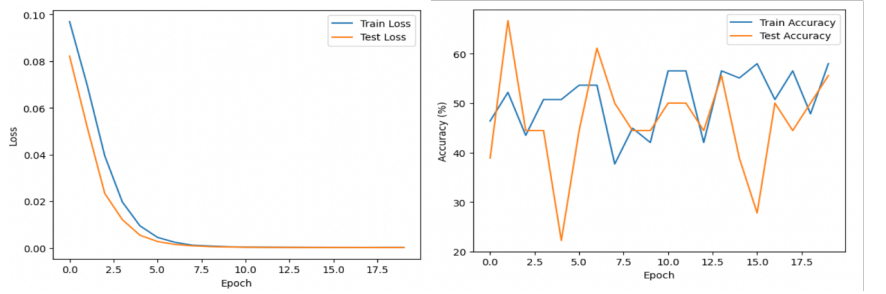
Through this model development, implementation, and evaluation we have explored the capacity of seq2seq with GRU and Attention, alongside Encoder BERT models, to predict future ICD-10 diagnosis codes. By combining natural language processing techniques with traditional methods, we successfully generated sequences of ICD-10 codes as well as binary predictions as output from the models. While the respective loss values for both sets of models were minimized across progressive epochs, the other evaluation metrics, specifically accuracy, give us pause as to the efficacy of the implementation in a real-world business or medical context. For instance, while the decreasing perplexity scores for the BERT models during testing indicate the model is understanding the context of the medical codes, the varying levels of accuracy would not satisfy benchmarks or standards for healthcare providers. Therefore, this model shows the potential to achieve the stated business objectives of predicting sequences of ICD-10 codes and thus improving patient health outcomes and decreasing hospital costs, but it needs further development before it is ready for deployment.
Skills
- Data cleaning and aggregation
- Predictive modelling
- Natural language processing (NLP)
- Sequence prediction models (seq2seq)
- Transformer models (BERT)
- Predictive modelling
- Natural language processing (NLP)
- Sequence prediction models (seq2seq)
- Transformer models (BERT)